JulyGPT: A Transformer-Based Auto-Regressive Language Model for Low-Resource Bengali Text Generation
Abstract:
JulyGPT বাংলা ভাষার ভাষাগত জটিলতা এবং ডেটা স্বল্পতা (Data Scarcity) বিবেচনা করে ডিজাইন করা একটি Stochastic Large Language Model (LLM) মডেল। বৈশ্বিক "Sovereign AI" বা সার্বভৌম এআই প্রযুক্তির ধারণা এবং বাংলাদেশের "জুলাই গণঅভ্যুত্থানের" ঐতিহাসিক প্রেক্ষাপট থেকে অনুপ্রাণিত হয়ে এই ১৩০ মিলিয়ন প্যারামিটারের মডেলটি ডেভেলপ করা হয়েছে। NVIDIA A100 Tensor Core GPU-তে ট্রেইন করা এই মডেলটি একটি Decoder-only Transformer Architecture অনুসরণ করে তৈরি টেক্সট বেজড এআই মডেল। মডেলটি Syntactic Coherence বজায় রেখে বাংলা টেক্সট জেনারেট করতে এবং সাধারণ Inference প্রদানে সক্ষম।
Introduction:
কৃত্রিম বুদ্ধিমত্তার গণতন্ত্রীকরণ (Democratization of AI) এবং Open-weights মডেলের বৈশ্বিক প্রভাব আমাদের নিজস্ব প্রযুক্তিগত জাতীয় সক্ষমতা বা AI Sovereignty অর্জনে আমাদের টিম কে উদ্বুদ্ধ করেছে। NLP ডোমেইনে বাংলা একটি Low-Resource Language হিসেবে বিবেচিত। JulyGPT প্রজেক্টের মূল লক্ষ্য হলো এই শূন্যস্থান পূরণ করা, এআই রিসার্চ এর জগতে বাংলাদেশের উপস্থিতি নিশ্চিত করা এবং একইসাথে জুলাই বিপ্লবের স্মৃতিকে একটি ডিজিটাল Knowledge Base-এর মাধ্যমে সংরক্ষণ করা। এটি একটি ননপ্রফিট Proof-of-Concept প্রোজেক্ট যা প্রমাণ করে যে সঠিক অপ্টিমাইজেশন টেকনিক ব্যবহার করে সীমিত রিসোর্সেও দেশীয় নিজস্ব প্রযুক্তিতে জেনারেটিভ এআই তৈরিতে বাংলাদেশ সক্ষমতা অর্জন করেছে এবং জাতীয় বিভিন্ন সমস্যায় নিজস্ব এআই প্রযুক্তি ব্যবহারে বাংলাদেশ সক্ষম।
Methodology & Architecture:
মডেলের Knowledge Representation সমৃদ্ধ করার জন্য আমরা বিভিন্ন High-fidelity sources ব্যবহার করেছি যার প্রাথমিক উৎস ছিল বাংলা উইকিপিডিয়া ডাম্প এবং Bengali.AI করপাস। ডেটা স্যানিটাইজেশনের জন্য আমরা একটি কাস্টম ডেটা পাইপলাইনের মাধ্যমে টেক্সট থেকে Non-Unicode artifacts এবং HTML tags রিমুভ করেছি। টোকেনাইজেশনের ক্ষেত্রে আমরা পিকিং ইউনিভার্সিটির ডেভেলপ করা Byte-Pair Encoding (BPE) টোকেনাইজার ব্যবহার করেছি। এটি বাংলা ভাষার Agglutinative (যুক্তবর্ণ ও বিভক্তিযুক্ত) বৈশিষ্ট্যের সাথে সামঞ্জস্যপূর্ণ, যা প্রচলিত টোকেনাইজারগুলোর তুলনায় Out-Of-Vocabulary (OOV) রেট উল্লেখযোগ্যভাবে কমিয়ে এনে আমাদের চমকপ্রদ ফলাফল প্রদান করেছে।
কম্পিউট সীমাবদ্ধতার কারণে আমরা Decoder-only Transformer আর্কিটেকচার বেছে নিয়েছি। হাইপারপ্যারামিটারগুলো টিউন করার ক্ষেত্রে আমরা মোট প্রায় ১৩০ মিলিয়ন প্যারামিটার (Dense) এবং ১৫০ টোকেনের কনটেক্সট উইন্ডো নির্ধারণ করেছি যা Short-sequence reasoning এর জন্য অপ্টিমাইজড। আর্কিটেকচারে ১২টি লেয়ার এবং ১২টি অ্যাটেনশন হেড ব্যবহার করা হয়েছে। মডেলটির এম্বেডিং ডাইমেনশন (\(d_{model}\)) হলো ৭৬৮ এবং অ্যাটেনশন মেকানিজম হিসেবে Multi-Head Self-Attention (MHSA) এর সাথে Causal Masking ব্যবহার করা হয়েছে।
Training Dynamics:
মডেলটি ট্রেইন করার জন্য হাই-পারফরম্যান্স কম্পিউটিং (HPC) এনভায়রনমেন্টে NVIDIA A100 (Tensor Core) এক্সিলারেটর ব্যবহার করা হয়েছে। রিসোর্স এফিশিয়েন্সি নিশ্চিত করতে এবং GPU Throughput সর্বোচ্চ ব্যবহার করতে আমরা দীর্ঘ ১০ মাস ধরে ধাপে ধাপে (Longitudinal Period) ট্রেনিং প্রক্রিয়াটি সম্পন্ন করেছি। এই দীর্ঘ সময়সীমা আমাদের মডেলের Learning Curve নিখুঁতভাবে মনিটর করতে এবং Hyperparameter Tuning-এ নমনীয়তা বজায় রাখতে সাহায্য করেছে। Tensor Cores এর ব্যবহার ম্যাট্রিক্স মাল্টিপ্লিকেশন অপারেশনগুলোকে ত্বরান্বিত করেছে, যা সীমিত হার্ডওয়্যারেও বড় মডেল ট্রেনিং সম্ভব করেছে।
মডেলের Convergence নিশ্চিত করতে আমরা সাধারণ SGD-এর পরিবর্তে AdamW Optimizer (\(\beta_1=0.9, \beta_2=0.95\)) ব্যবহার করেছি, যা ল্যাঙ্গুয়েজ টাস্কের ক্ষেত্রে Sparse Gradients হ্যান্ডেল করতে অত্যন্ত কার্যকর। মেমোরি বা VRAM Footprint কমানোর পাশাপাশি কম্পিউটেশনাল স্পিড বাড়ানোর জন্য আমরা Mixed Precision Training (FP16) প্রযুক্তি ব্যবহার করেছি। এটি আমাদের বড় Batch Size নিয়ে কাজ করার সুযোগ দিয়েছে। মডেলের পারফরম্যান্স পরিমাপের জন্য এবং প্রেডিক্টেড ও একচুয়াল টোকেন ডিস্ট্রিবিউশনের পার্থক্য কমাতে স্ট্যান্ডার্ড Cross-Entropy Loss ফাংশন ব্যবহার করা হয়েছে।
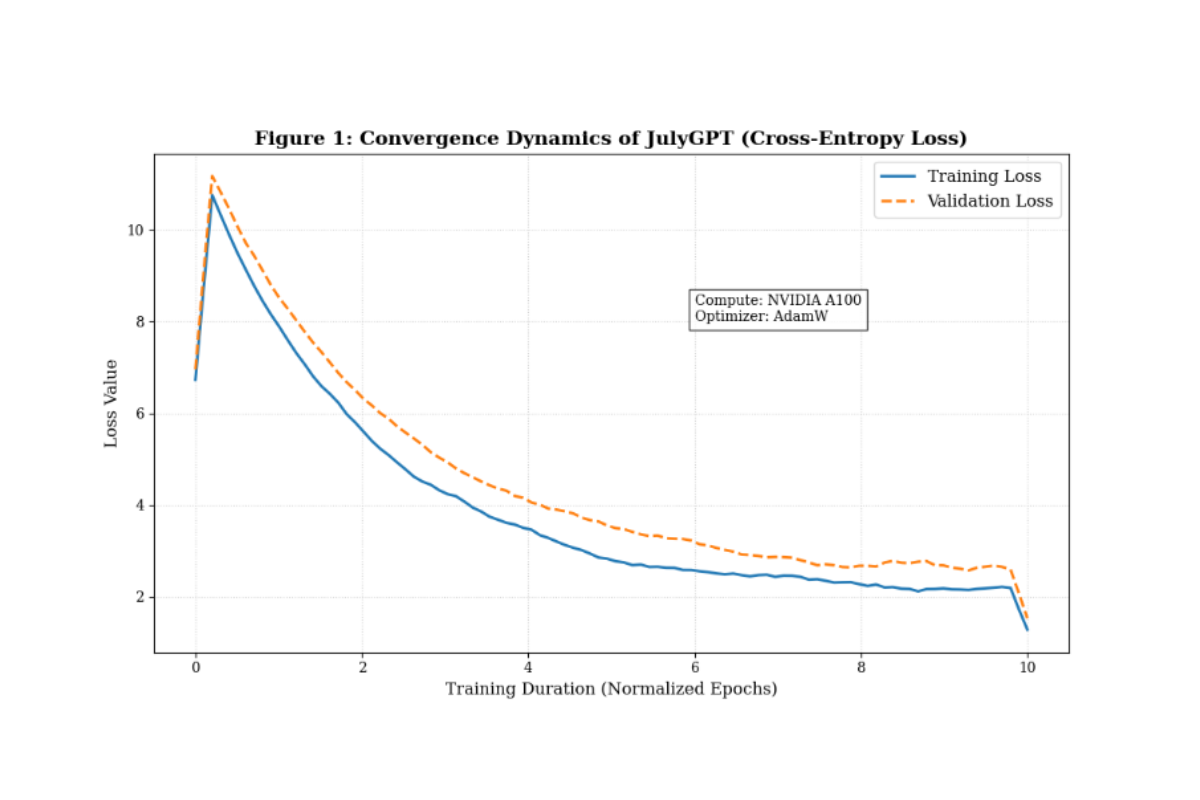
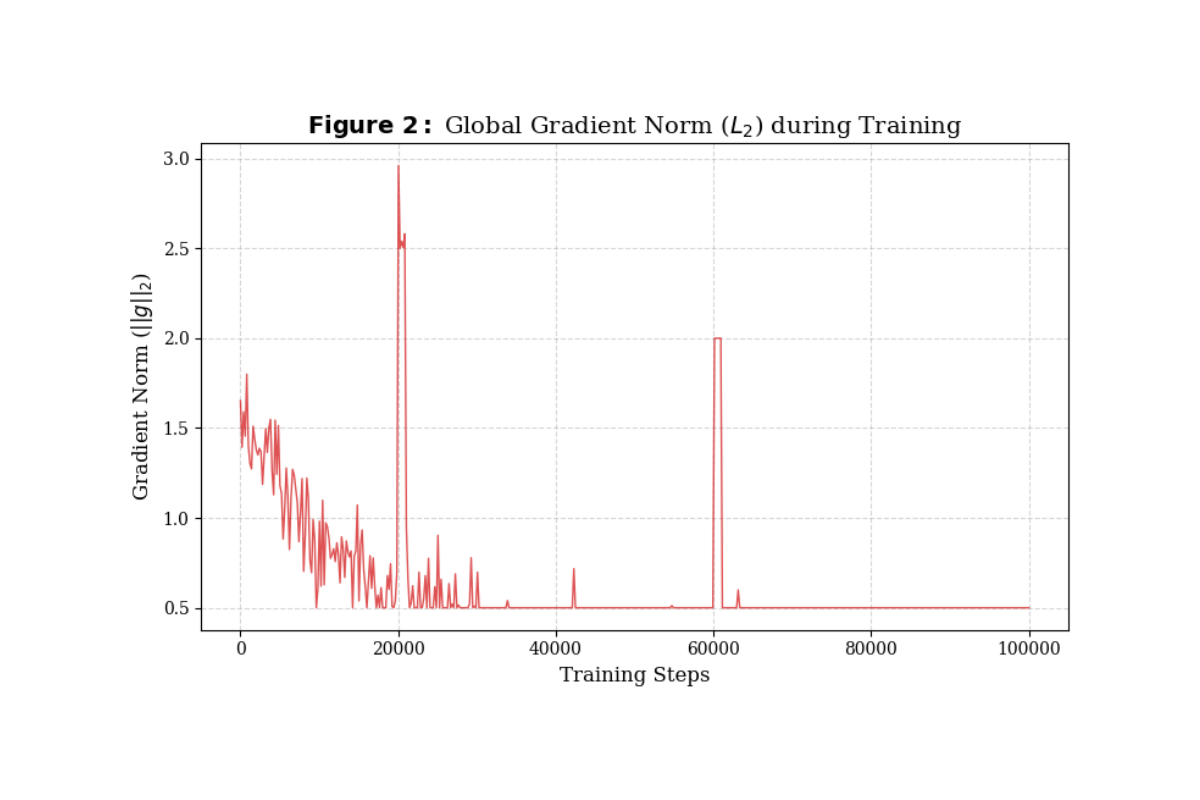
ট্রান্সফরমার মডেল ট্রেনিংয়ের ক্ষেত্রে Training Stability একটি বড় চ্যালেঞ্জ। আমরা ট্রেনিংয়ের প্রাথমিক ধাপে বেশ কিছু 'Gradient Spike' লক্ষ্য করি। এই সমস্যা সমাধানের জন্য আমরা Gradient Clipping (Norm 1.0) টেকনিক ইমপ্লিমেন্ট করি। এটি গ্রেডিয়েন্ট ভ্যালুকে একটি নির্দিষ্ট সীমার মধ্যে রাখে, যার ফলে মডেলটি Diverge করেনি বা Catastrophic Forgetting-এর শিকার হয়নি। নিচের গ্রাফে দেখা যায় যে, ক্লিপিং ব্যবহারের ফলে পুরো ট্রেনিং সেশন জুড়ে Gradient Norm অত্যন্ত স্টেবল ছিল।
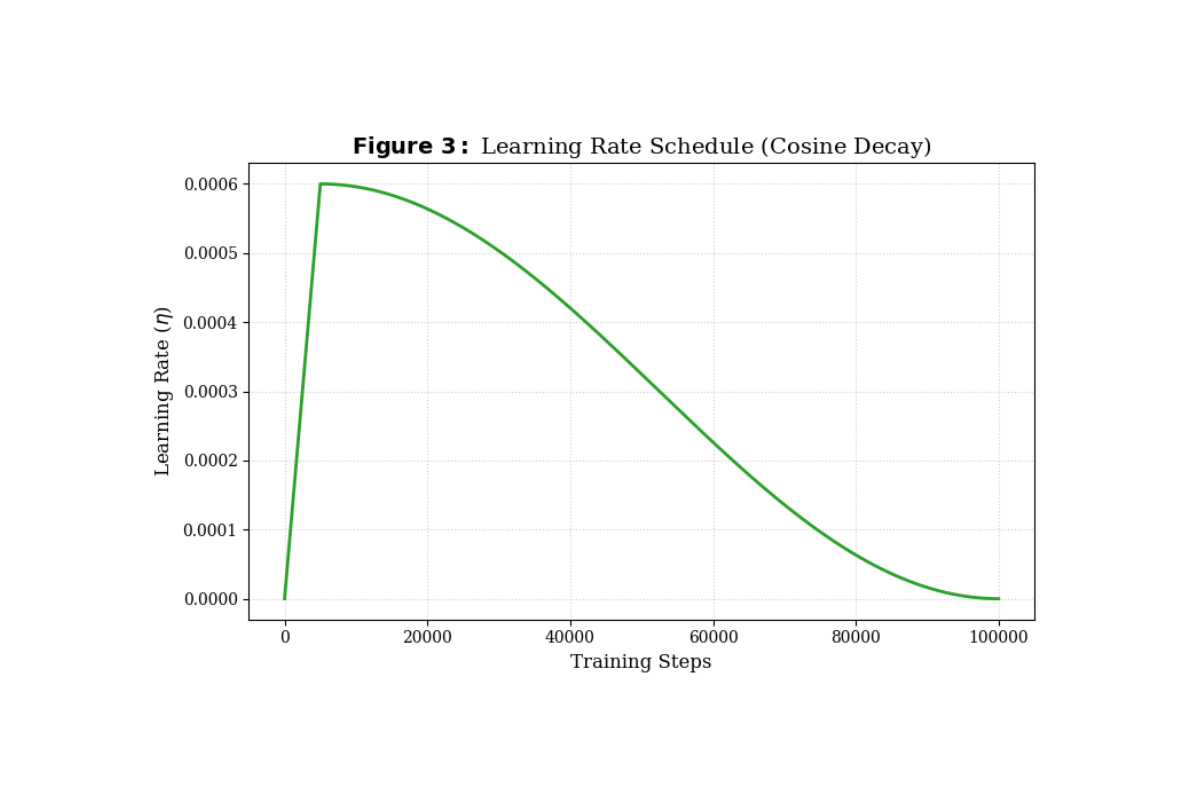
আমরা কনস্ট্যান্ট লার্নিং রেট ব্যবহারের পরিবর্তে একটি ডায়নামিক শিডিউল অনুসরণ করেছি। ট্রেনিংয়ের শুরুতে আমরা Linear Warmup মেকানিজম ব্যবহার করেছি, যা মডেলের Embeddings এবং ওয়েটগুলোকে ধীরে ধীরে অ্যাডজাস্ট হতে সাহায্য করে এবং মডেলকে ইনিশিয়াল শক থেকে রক্ষা করে। পরবর্তী ধাপে আমরা Cosine Decay স্ট্র্যাটেজি ব্যবহার করেছি, যা লার্নিং রেট ধীরে ধীরে কমিয়ে আনে। এই পদ্ধতি মডেলকে অপ্টিমাইজেশন ল্যান্ডস্কেপের Global Minima-তে সেটল হতে এবং জেনারেলাইজেশন সক্ষমতা বাড়াতে সহায়তা করেছে।
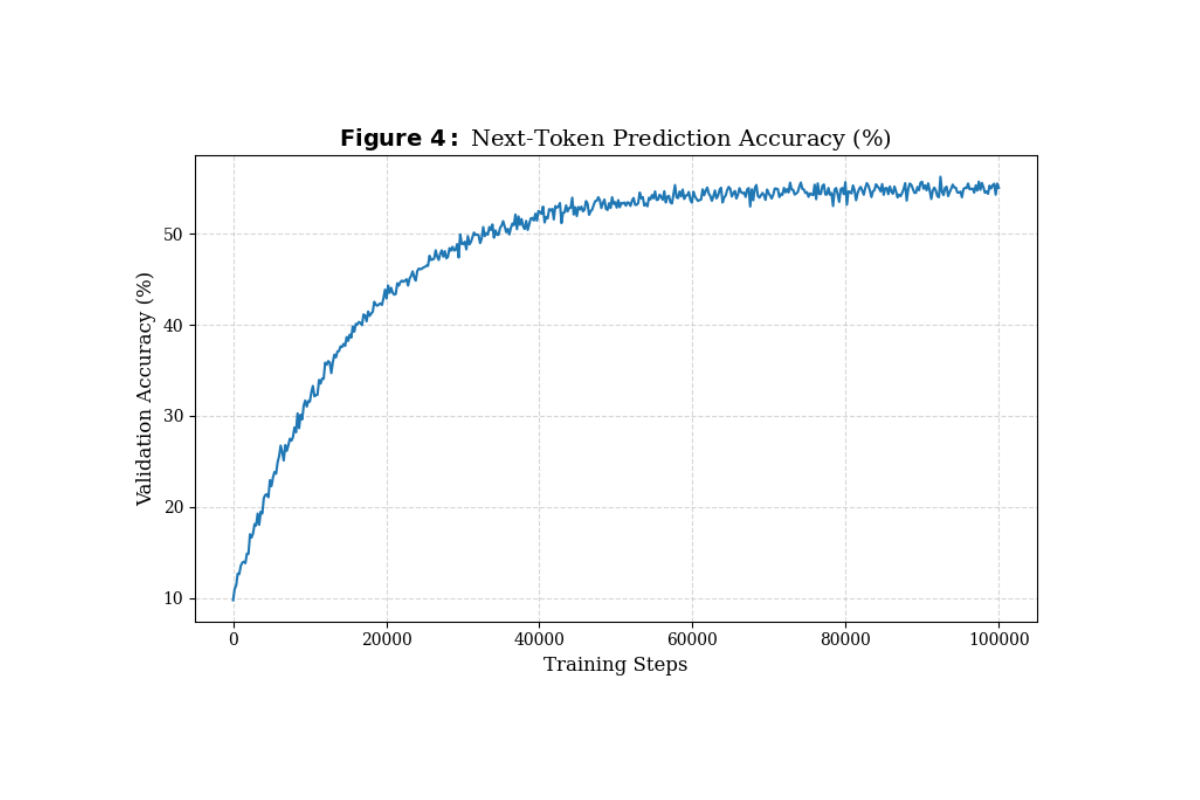
Training Loss কমার পাশাপাশি আমরা মডেলের ভ্যালিডেশন মেট্রিক্স পর্যবেক্ষণ করেছি। ফলাফলে দেখা গেছে, মডেলের Next-token prediction accuracy সময়ের সাথে সাথে বেড়ে প্রায় ৫০-৫৫% এর দিকে কনভার্জ করেছে। বাংলা ভাষার মতো একটি Low-Resource Language-এর জন্য ১৩০ মিলিয়ন প্যারামিটারের মডেল থেকে এমন একুরেসি পাওয়া মডেলের শক্তিশালী Pattern Recognition এবং Semantic Understanding ক্ষমতার প্রমাণ দেয়।
Conclusion
JulyGPT কেবল বাংলা ভাষায় একটি এআই মডেল নয়, এটি একটি ডিজিটাল মনুমেন্ট। এটি একটি Non-Profit Research Initiative, যা জুলাইয়ের শহীদ ও যোদ্ধাদের আত্মত্যাগের প্রতি উৎসর্গকৃত। দেশীয় গবেষণার স্বার্থে GPU (NVIDIA A100/H100) আমদানির ওপর ট্যাক্স মওকুফ বা যৌক্তিক পর্যায়ে নামিয়ে আনার জন্য আমরা বাংলাদেশ এআই রিসার্চার কমিউনিটি থেকে সরকারের কাছে জোর সুপারিশ করছি।
মানুষের মধ্যে বৈষম্যের সূচনা হয় সঠিক ও উচ্চশিক্ষায় সমান একসেস না থাকার কারণে। আমাদের দেশের গ্রামাঞ্চলের সাধারণ শিক্ষার্থীরা ভালো মানের শিক্ষক, রাইট টুলস ও এডুকেশনাল মেটেরিয়াল না থাকার ফলে বিজ্ঞান শিক্ষায় যুগের পর যুগ ধরে সহজেই পিছিয়ে পড়ছে। এআই ব্যবহার করে আমরা আমাদের দেশের এরকম সমস্যাগুলো দারুনভাবে সমাধান করতে পারি। এআই রিসার্চার কমিউনিটির মেম্বার হিসেবে আমরা মনে করি, বৈশ্বিক পরিমন্ডলের সাথে তাল মেলাতে বাংলাদেশের National AI Policy বাস্তবায়নের এখনই উপযুক্ত সময়। JulyGPT একটি সূচনা মাত্র। ১৩০ মিলিয়ন প্যারামিটারের এই মডেলটি প্রমাণ করে যে, সদিচ্ছা এবং সঠিক প্ল্যান থাকলে বাংলাদেশও গ্লোবাল এআই রেসে অংশ নিতে পারে। আমরা খুব শীঘ্রই এই মডেলটিকে আরও বড় স্কেলে (Scaling & Fine-tuning) নিয়ে যেতে সক্ষম হবো বলে আশা রাখি এবং সমর্থন প্রত্যাশা করি।
JulyGPT Research by Bunon AI Labs | 2025